

השורות הבאות פונות ל- SEO Professional ול- Website Developer עם עניין לשפר את יכולות ה- Technical SEO ולהבין למעשה איך מנוע החיפוש של גוגל עובד.
במאמר זה אפרט עבורך את 5 השלבים מגילוי העמוד ועד הדירוג שלו בגוגל, יכול להיות שאתעמק גם במידע טכני. בכל מקרה אשדל להיות קצר ולעניין ככול הניתן.
כאשר הנקודה הכי חשובה שצריך להבין לפני שמתחילים לקרוא את המאמר כאן – טעות או שגיאה אחת באחד מ- 5 השלבים המוזכרים פה, יכולה למנוע מהצגת עמוד אתר האינטרנט להופיע בתוצאות החיפוש של גוגל, וכן בשאר מנועי החיפוש.

5 השלבים בתהליך של גוגל לדירוג עמוד
גילוי (Discover)
גילוי העמוד על ידי קישור פנימי, קישור חיצוני, הרשמת ה- URL של העמוד בגוגל או דרך ה- Site Map XML.
זחילה (Crawl)
מציאת כל המשאבים של העמוד (JS, CSS, תמונות וכו') מתוך ה- HTML הראשוני והוספתו והמשאבים הנלווים לו לתור – איזה תור? נבין בהמשך המאמר.
רינדור (Render)
מנוע החיפוש גולש דרך הדפדפן (במקרה של גוגל ב- Chrome) ומנסה להבין מה הגולש רואה (מבחינת השוואה לכלל מנועי החיפוש, לגוגל ישנה את יכולת הרינדור הגבוהה ביותר).
אינדוקס (Index)
גוגל מקבלת החלטה מה לעשות עם העמוד, ובמידת הצורך מוסיפה את העמוד לאינדקס שלה כחלק מאוסף של כל העמודים.
דירוג (Rank)
גוגל מדרגת את העמוד על בסיס פרמטרי דירוג שונים. בגדול על בסיס 4 פרמטרים עיקריים: איכות, רלוונטיות, פופולריות וסמכותיות.
הסברתי לעומק על 4 פרמטרי הדירוג הנ"ל במאמר על קידום אורגני.
במאמר הנוכחי אני הולך להעמיק ב- 3 שלבים בלבד מתוך ה- 5:
- זחילה (Crawl)
- רינדור (Render)
- אינדוקס (Index)

מבחינת גילוי ודירוג, אני לא הולך להרחיב דבר ולהתעמק בהם בכלל כאן. רק אציין שאחת הבדיקות החשובות כדי לוודא שאכן הקישורים הפנימיים באתר אכן תקינים היא שאכן מדובר על קישורי a href.
משמע לא קישורי JS (מלשון Java Script) ולא כפתורים (כחלק מתג button ב- HTML, למרות שקישור תקין אכן יכול להיראות כמו כפתור).
אז נתחיל.
זחילה – Crawl
מי "שזוחל" לנו באתר הוא גוגל בוט (Googlebot) שלמעשה ההבדל העיקרי בינו לבין משתמש רגיל הוא ה- User Agent (שורת טקסט המזהה את הדפדפן ומערכת ההפעלה של המשתמש שגולש לנו באתר), כאשר לבוטים ידועים ישנם User Agent ייחודי.
קצת על Robots.txt
בזחילה של הבוטים השונים שמנועי החיפוש שולחים אל האתר שלנו, אנחנו "שולטים" בעזרת מסמך הנקרא robots.txt – שהוא למעשה סט הוראות לבוטים השונים, איפה מותר להם לזחול באתר שלנו ואיפה בעיקר אסור להם לזחול באתר.
כמו כן, ניתן להגדיר בו את כתובת או כתובות מפות האתר שלנו (Site Map XML)
- הסיבה שכתבתי שולטים עם מירכאות – היא מכוון שבוטים רעים, לא יקשיבו להנחיות למעשה יעשו לך דווקא.
כמו כן, אם ישנו עמוד עם הוראת No Index עלייה אפרט בשלב האינדוקס, במידה ואותו עמוד זוכה לקישור פנימי מהאתר או מאתר חיצוני אבל חסום לסריקה מבחינת ה- Robots.txt, עדיין יש סיכוי שגוגל יאנדקס אותו. כי גוגל לא יכנס אל העמוד כדי לקרוא בו את הוראת ה- No Index.
בגדול המטרה העיקרית של קובץ ה- Robots.txt היא למנוע מבוטים שונים להעמיס על האתר עד כדי שגיאות שרת ונפילת האתר.
עמודים שאנחנו רוצים שגוגל יאנדקס וידרג בתוצאות החיפוש שלו עם ביטויים רלוונטיים, חשוב שלא יחסמו לסריקה על ידי Robots.txt.
מנוע חיפוש אחד – הרבה זוחלים
בעוד שנהוג לחשוב כי Googlebot הוא בוט אחד ומיוחד, למעשה מדובר על משפחה שלמה של זוחלים, בוטים מבית גוגל (כמו אגב לשאר מנועי החיפוש) שלכל אחד מהם מטרה מסוימת ו- User Agent משל עצמו.
כך יש בוט של גוגל לסריקת תמונות האתר, בוט לוידאו, בוט לחדשות, בוט למובייל, בוט ל- Desktop, ועוד.

תקציב הזחילה
ככול שגוגל זוחל באתר שלך יותר, ככה הוא לומד את האתר שלך טוב יותר, מה שעוזר לאתר שלך להתקדם על מגוון ביטויים רחב יותר בתוצאות החיפוש.
רק שמכוון שחשוב לגוגל לא לגרום לאתר האינטרנט שלך לקרוס, יש מושג שקהילת מקדמי ה- SEO יצרה וגוגל אימץ – "תקציב זחילה", שלפי רוב אומר כי הזחילה של הבוטים של גוגל באתר האינטרנט שלך מוגבלת.
למעשה זה לא באמת המצב אבל כן יש דבר כזה, ולכן זה מבלבל וכעת אני אסביר.
גוגל מצהירה כי היא משקיע כמה זמן שנדרש כדי לסרוק / לזחול באתר אינטרנט, בהתייחס לגודל שלו, תדירות העדכונים שלו, איכות העמודים שלו והרלוונטיות שלו בהשוואה לאתרי אינטרנט אחרים.
כאשר גוגל מתחשבת ב- 3 פרמטרים עיקרים כדי לקבוע את הדרישה לזמן הסריקה:
- הנחייה או חוסר בהנחייה של אילו עמודים לסרוק.
- פופולריות – עמודים בעלי פופולריות גבוהה ברחבי האינטרנט זוכים לסריקה בתדירות גבוהה יותר
- עדכניות – לגוגל חשוב להיות מעודכנים בכל שינוי קטן בעמודי האתר, ולכן הם יסרקו בתדירות גבוהה יחסית עמודים אשר עושים שינויים בתדירות גבוהה.
מנגד לזאת אכן יש תקציב זחילה, תקציב הזחילה מושפע מ- 3 פרמטרים:
- בריאות הזחילה (Crawl Health) – אם אתר האינטרנט מגיב במהירות וללא שגיאות שרת, מגבלת תקציב הזחילה עולה. אם אתר האינטרנט מגיב לאט או מגיב בשגיאות שרת, HTTP או DNS שונות אז המגבלה יורדת, וגוגל Bot זוחל פחות.
- בנוסף אפשר לשלוט בתקציב הזחילה באופן ידני דרךGoogle Search Console (מה שלא מומלץ).
- לגוגל ישנה הגבלה משל עצמה – לגוגל ישנן הרבה מאוד מכונות (בוטים) אשר סורקות את האינטרנט, אבל לא אין סוף ולכן גוגל עדיין צריכה לעשות בחירה אילו משאבים שלה לנצל ועבור איזה אתרי אינטרנט.
קצת נתונים טכניים על זחילה על ידי Googlebot
למרות שישנם זוחלים רבים לגוגל, Googlebot בעיקר מתקשר לזחלן של גוגל לנייד, ולזחלן של גוגל ל- Desktop. כאשר הסריקה לרוב תהיה דרך Googlebot לנייד.
Googlebot זוחל מכתובות IP רבות, תלוי מדינה כדי לקצר את זמן הזחילה עד כמה שניתן. למרות זאת רוב הזחילות יהיו לרוב מארצות הברית – לכן רצוי לא לחסום סריקות מארצות הברית, בנוסף למרות שהרבה גולשים מזייפים את ה- User Agent לזו שגוגל, עדיין כדאי לא לחסום אותם (גם אם כתובת ה- IP לא מתקשרת לזו של גוגל).
אם אתר האינטרנט שלך תומך ב- HTTP/2 גוגל יעשה בו שימוש, כדי לסרוק את האתר ולהוריד כמה שיותר קבצים בו זמנית, מה שעשוי לחסוך משאבי מחשוב של השרת שלך ועבור Googlebot. למרות זאת – אם האתר לא תומך ב- HTTP/2, גוגל עדיין יסרוק את האתר, אבל על ידי HTTP/1.1.
הבוט של גוגל יכול לסרוק עד 15 מגה בייט הראשונים של קובץ HTML או פורמט מבוסס טקסט אחר, אשר נתמך – לדוגמה PDF. כל ה- 15 מגה שלאחר מכן, גוגל יתעלם מהם לצורך דירוג האתר.
כל המשאבים האחרים הכוללים בעמוד ה- HTML (לדוגמה: סרטונים, CSS, תמונות ו- JS) נשלפים בנפרד לטובת שלב הרינדור.

רינדור – Render
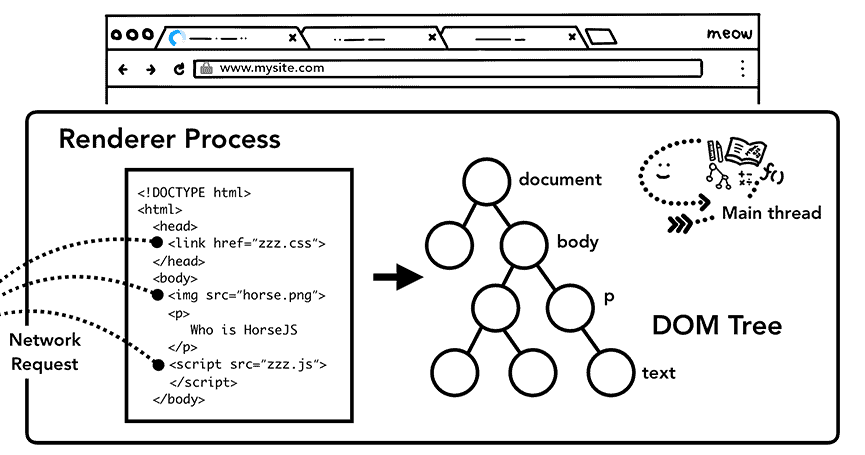
רינדור הוא תהליך המתחרש בכלל הדפדפנים המודרניים כיום, העושה שימוש ב- HTML ראשוני (Initial HTML) והופך אותו ל- HTML מרונדר (Rendered HTML), או במילים פשוטות: רינדור הוא תהליך המרה של סט הוראות טקסט (HTML) לעמוד האינטרנט הוויזואלי שלנו.
הליך הרינדור מורכב ב- Fetching (איסוף כלל המשאבים שהזחלן איתר בשלב ה- Crawl) ועל ידי שימוש ב- HTML הראשוני, מנסה להבין על מה העמוד מדבר, איפה למקם כל תמונה, או למקם את הטקסט וכן הלאה.
HTML מרונדר ידוע בעיקר בשם DOM. הרבה חושבים שתהליך רינדור מיועד רק ל- JS, אבל למעשה הוא קורה עבור כל משאב בעמוד האינטרנט שלנו.
למרות זאת, גוגל אכן מחקה אחר הגולש ומנסה לראות את מה שהוא רואה.
ועל כן עושה שימוש בדפדפן כרום כדי לרנדר את עמוד האינטרנט אצלה תוך כדי שהיא גם מריצה את ה- JS שבעמוד, שכן JS יכולה להוסיף ולהסיר תוכן מהעמוד, שיכול להיות מאוד קריטי לתוצאה הוויזואלית של כלל עמוד האינטרנט הסופי שלנו.
מה שגוגל לא מצליחה לרנדר היא גם לא תאנדקס בשלב האינדוקס.
זו גם הסיבה מדוע רינדור האתר בצד השרת (בשוני מצד הדפדפן) כה חשוב, או יותר טוב מזה, כאשר הדבר אפשרי – שליחת גרסה סטטית, ישירות לדפדפן, מבלי הצורך לרנדר אותה בצד השרת או בצד הדפדפן.
רינדור הוא חלק מקביל לאינדוקס העמוד בגוגל
למרות שנכון להגיד שתהליך כל עמוד חדש באתר האינטרנט שלנו כדי להופיע בתוצאות החיפוש בגוגל, צריך לעבור 5 שלבים:
- גילוי
- זחילה
- רינדור
- אינדוקס
- דירוג
למעשה גוגל יכולה לאנדקס את ה- HTML הראשוני כבר מייד לאחר שלב הזחילה, בתנאי שאין משאבים חוסמים, וכבר לאנדקס את העמוד לפי אותם פרמטרים מבלי להתייחס לשלב הרינדור שלמעשה קורה במקביל, ולא יוצר צוואר בקבוק.
בעיקר (אם לא רק), לפי החלק הקיים בתוך התג ה- HEAD.
רינדור הוא דבר יקר
תהליך רינדור של הדפדפנים השונים משפיע על ה- CPU מצד אחד ומהצד השני על רכיבי ה- O/I אשר בעולם האינטרנט בין שרתים זולל זמן יקר, שני רכיבים המשפיעים גם על תקציב הזחילה. כמו כן על חוויית הגולש.
כאשר המשאבים אשר משפיעים ביותר על CPU ועל זמן ה- O/I הם קבצי JS. הדרך לטפל בזה בגדול זה על ידי איחוי קבצי טעינת אתר האינטרנט.
בקטן הדרך לטפל בזה תהיה:
- לעלות את כל תגי המטה (Meta) השונים למעלה מעל הכל (בתוך ה- Head)
- לפצל קבצי JS לקבצים קטנים יותר ולחלק אותם לפי מה מתעדכן ומה לא עתיד להתעדכן (או מתעדכן בתדירות יחסית נמוכה)
- להוציא את כלל קבצי ה- JS מתוך ה- Head ולקרוא להם רק כאשר יש צורך לעשות בהם שימוש
- להוסיף לכלל קבצי האתר קאש' – כדי שגוגל וגולשי האתר לא יצרכו לרנדר את כלל הקבצים בכל פעם מחדש
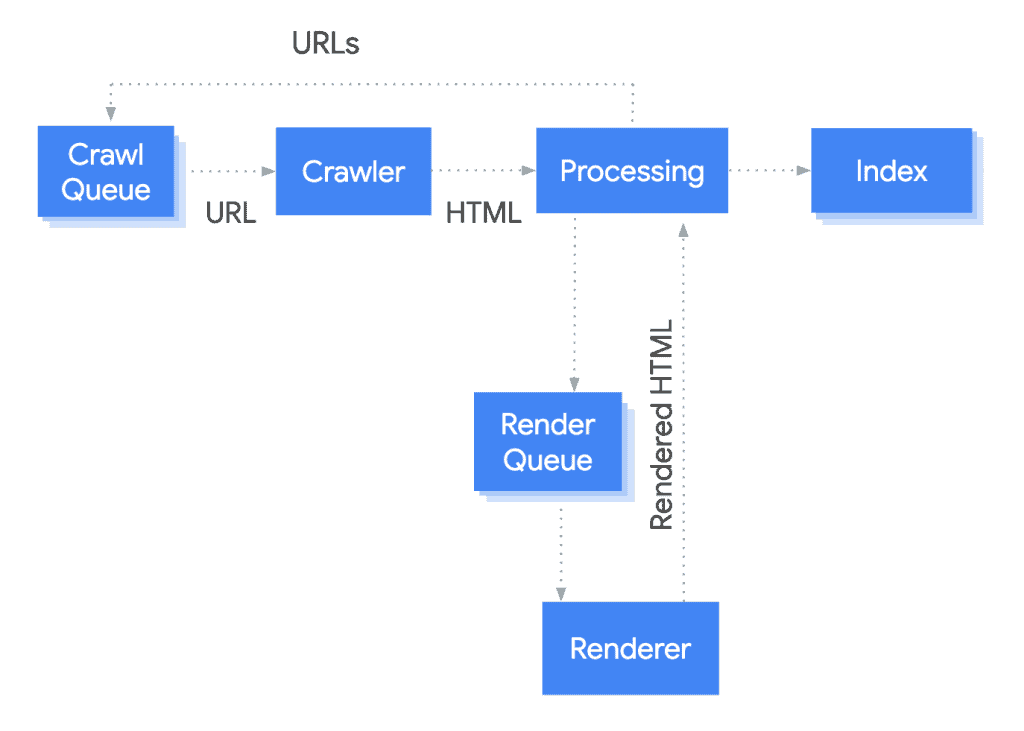
לאחר הרינדור, בתנאי שאין כל בעיות, נעבור לשלב האינדוקס.
אינדוקס – Index
בשלב האינדוקס גוגל מנתחת ומעבדת את תוכן העמוד ואת המשמעות שלו ומאחסנת את כל המידע הזה במסד נתונים הנקרא Google Index, על מנת להציג אותו בהמשך הדרך בעמוד תוצאות החיפוש (SERP – Search Engine Results Page).
זאת כמובן בתנאי שהעמוד עומד בכלל הנחיות ה- SEO של גוגל, ואיננו חסום לאינדוקס על ידי תג ה- Meta Data המורה למנועי החיפוש לא לאנדקס את העמוד:
- כמובן, כפי שהזכרתי עוד קודם לכן במקרה שישנו התג Noindex כמו בדוגמה למעלה, ובנוסף העמוד חסום לזחילה על ידי קובץ ה- txt עדיין ישנה סבירות כי העמוד יאונדקס אבל מבלי שגוגל יראה מה הוא מהכיל בתוכו.
תהליך הוספת העמוד ל- Google Index
במהלך תהליך הוספת העמוד ל- Google Index גוגל בודקת האם אותו עמוד הוא עמוד משוכפל של עמוד אחר באינטרנט, או מהאתר עצמו, או עמוד ייחודי שאין שני לו.
אם גוגל תחליט שאותו עמוד הוא תוכן זהה לאותו עמוד שכבר קיים ברחבי האינטרנט, היא תאנדקס את העמוד באשכול עמודים של קבוצת העמודים הזהה ותחליט אילו מהעמודים אכן מייצגים הכי טוב את התוכן הדומה כדי להציג אותם.
את שאר העמודים החלופיים באשכול, גוגל עשויה להציג ב- SERP בהקשרים שונים כאשר המשתמש מחפש ממכשיר שונה שהתוכן יותר מותאם לו, ממדינה או לפי פרמטרים שונים בחיפוש הגולש.
בנוסף גוגל אוספת ומאחסנת אצלה מידע נוסף (Signals) היכול להיות רלוונטי לגולש, בהמשך הדרך, דוגמת:
- שפת העמוד
- המדינה שהתוכן רלוונטי אליה
- התפקיד של העמוד
- יוצר העמוד
- המקור ממנו גוגל נחשפה לעמוד בפעם הראשונה
- התאריך בו העמוד נצפה על ידה לראשונה
ועוד.
בכל מקרה גוגל לא מבטיחה שהיא תאנדקס כל עמוד תקין שהיא מנתחת ומעבדת, אז הלכת כמה וכמה עמודים לא תקינים.
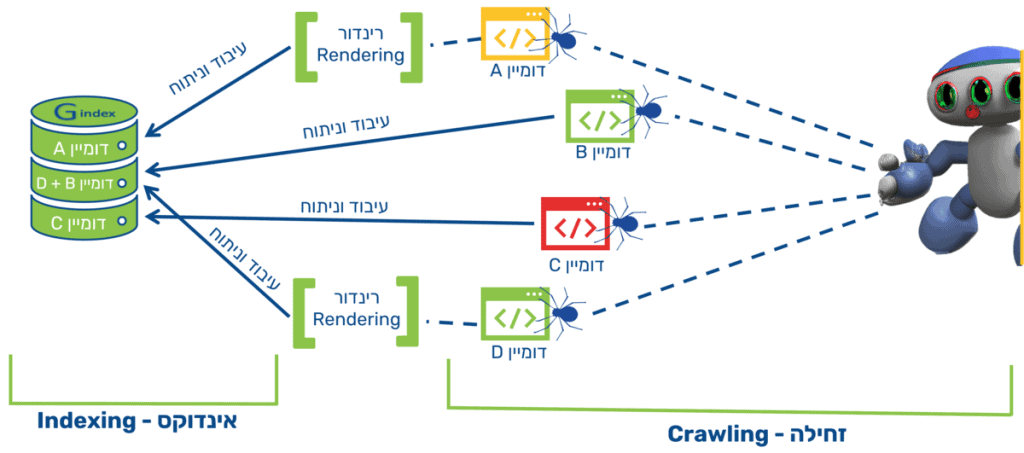
אילו שגיאות או טעויות יכולות למנוע אינדוקס של עמוד אינטרנט?
- איכות תוכן של עמוד נמוכה
- עיצוב אתר אינטרנט המקשה על אינדוקס העמוד
- הנחיות מטא של robotsהאוסרות על יצירת אינדקס
אעמיק בשתי הנקודות הראשונות:
איכות תוכן נמוכה
למעשה איכות התוכן מורכבת מ- 3 פרמטרים החיוניים לתוכן עמוד האינטרנט שלך:
- דרישות טכניות
- מדיניות הספאם של גוגל
- הנחיות האלגוריתם של גוגל
דרישות טכניות
- גוגל בוט לא חסום מהעמוד
- העמוד עובד באופן תקין (מספק סטטוס קוד HTTP- 200)
- העמוד כולל קבצים שגוגל תומך בהם
- העמוד לא עובר על מדיניות הספאם של גוגל
אלה הן הדרישות הטכניות לפי גוגל, אני אוסיף עליהן גם:
קוד Title, דיסקרפשיין, וקנוניקל תקין, הנמצאים בשורות הראשונות של הקוד בתוך ה- Head. למעשה ההמלצה שלי היא כי כלל תגי המטא צריכים להיות ראשונים בקוד מעל כל הקריאות ל- CSS, פונטים, JS תמונות וכו'.
מדיניות הספאם של גוגל
מדיניות הספאם של גוגל בודקת שהעמוד או אפילו עמוד אחר באתר האינטרנט, איננו כולל את אחד הסעיפים הבאים:
- הסוואה (Cloaking)
- פתחים (Doorways)
- תוכן זדוני (Hacked Content)
- טקסט וקישורים מוסתרים (Hidden Text & Links)
- Keyword Stuffing
- קישורי ספאם (Link Spam)
- תעבורה שנוצרה על ידי מכונה (Machine-Generated Traffic)
- תוכנות זדוניות והתנהגויות זדוניות (Malware & Malicious Behaviors)
- פונקציונליות מטעה (Misleading Functionality)
- תוכן מגורד – מיובא מאתר אחר (Scraped Content)
- הפניות עמוד ערמומיות (Sneaky Redirects)
- תוכן שנוצר אוטומטית כספאם (ללא מקוריות או ערך מוסף – Spammy Automatically-Generated Content)
- דפי שותפים (מלשון תוכנית שיתופים ) דקים (כוללים רק את התיאור שכבר קיים באתר החיצוני) – Thin Affiliate Pages
- ספאם שנוצר על ידי משתתפים (User-Generated Spam)
למעשה אם לוקחים את כל 14 הסעיפים האלה ומנסים לסכם אותם להנחיות כלליות, ההבנה תהיה כי תוכן איכותי בעיניי גוגל הוא תוכן בטוח לגולשים אשר הוא בעל ערך מוסף ומקורי (גם אם חלק מעותק) ושהוא לא נכתב עבור מנועי החיפוש, אלא נטו עבור הגולשים.
כך שמה שגוגל רואה ומה שהגולש רואה אכן שווים ובעלי מסר דומה ושחלילה אין שום מידע מטעה בעמוד.

עיצוב אתר אינטרנט חברתי למנועי החיפוש (לא מה שחשבת)
עיצוב אתר אינטרנט חברתי למנועי החיפוש, הוא עיצוב אתר שלגוגל קל לאנדקס. שכן אחרת העיצוב עלול למנוע מהאתר להתאנדקס.
הנה רשימה של רכיבים או טכנולוגיות ששימוש בהם או חוסר שלהם עלולים להקשות על אתר האינטרנט להתאנדקס:
- חוסר בתגי מטא חיוניים או קובץ החוסם קריאה מהירה שלהם.
- קוד אתר מורכב מידי שגוגל לא הצליחה לרנדר
- שימוש שגוי בסטטוסי HTTP
- מבנה קישורים לא נכון בקוד ה- HTML של האתר
- תפקוד לקוי של פעולת קדימה ואחורה בדפדפן
- שגיאה ביצירת תג קנוניקל
- יצירת תגי מטא על ידי JS
- חוסר או חסימה של שמירת גרסת מטמון (קאש' – Cache) או תוקף קצר מידי
- תמונות השוקלות יותר מידי הפוגמות בטעינה הראשונה של העמוד
- אתר לא נגיש לאנשים עם צרכים מיוחדים או בעלי מכשירים אשר לא תומכים בטכנולוגיות מתקדמות
- עיצוב אתר אשר יישום שלו גורר ביצועי אתר גרועים
- חוסר בהיררכיה בין עמודי האתר השונים
במידה ואין כל שגיאות או טעויות כפי שפירטתי עד כה, נשאלת השאלה "כמה זמן לוקח לעמוד להיות מאונדקס בגוגל, ולהופיע בתוצאות החיפוש מרגע שפורסם?"
הזמן שלוקח לעמוד להתאנדקס
לפי ג'ון מולר מגוגל ישנם עמודים שיכול להיות שיהיו מאונדקסים תוך מספר שעות וישנם עמודים שיכול להיות שיהיו מאונדקסים תוך מספר שבועות אבל לא כל כל עמוד בטוח יהיה מאונדקס, וגם אלה שכבר מאונדקסים, יכול להיות שגוגל תסיר אותם מאינדוקס.
לפי מחקר שעשה תומק רודצקי (Tomek Rudzki) מ- Onely בנושא כ- 16% מהעמודים בממוצע מאתרי אינטרנט שונים לא מאונדקסים (למרות שישנם גם אתרים שכל העמודים שלהם מאונדקסים) כאשר הזמן שלוקח לכל עמוד להיות מאונדקס מצוין בטבלה הבא:
| הזמן שלוקח לגוגל לאנדקס את העמוד | האחוזים מהעמודים ברחבי האינטרנט שתוך אותו זמן כבר יהיו מאונדקסים* |
|---|---|
| יום אחד | 59% |
| 3 ימים | 74% |
| שבוע | 83% |
| שבועיים | 87% |
| חודשיים (8 שבועות) | 100% |
* במידה ובשלב מסוים אותם עמודים אכן יהיו מאונדקסים
הדבר אומר כי אם עברו חודשיים מרגע שפרסמת את העמוד האינטרנט שלך ואינך עדיין רואה את העמוד בתוצאות החיפוש של גוגל, הדבר אומר שככול הנראה אותו עמוד נכנס לסטטיסטיקה של 16% מהעמודים של אתרי האינטרנט אשר אינם מאונדקסים.
ועל כן, ככול הנראה יש בו שגיאה או טעות, שגיאה או טעות אשר אכן ניתן לטפל בה, ולפעמים אפילו דיי בקלות. או משהו אחר המונע מאותו עמוד להיות מאונדקס.
הדבר גם אומר, שאם לוקח יותר משבוע עד שעמודי אתר האינטרנט שלך מתאנדקסים בתוצאות החיפוש של גוגל, עדיין ישנה אופטימיזציה שניתן לבצע כדי לייצר אינדוקס מהיר של אותם העמודים לתוך ה- Google Index.
מילות סיכום על הדרך בה מנוע החיפוש של גוגל עובד
אני מקווה שכעת ברור לך איך גוגל עובד, איך עובד מנוע החיפוש שלהם ומתוך אותן מסקנות יתאפשר לך גם להבין מה נדרש ממך לשפר באתר האינטרנט שלך, בסביבתו ובעמודיו כדי לייצר את האימפקט הדרוש לך.
כמו כן, חשוב לזכור כי ישנם מנועי חיפוש חוץ מגוגל, אשר עובדים בדרך יחסית זהה אבל יכולות הרינדור שלהם פחות טובות. על כן כאשר מדברים על אופטימיזציה – חשוב לשאוף לסטנדרטים של גוגל.
וכאשר מדברים על רינדור, אנחנו נשתדל לייצר את אתרי האינטרנט הקלים ביותר עם הביצועים המקסימליים. דבר שגם טוב לחוויית המשתמשים שלנו.
להנחיית שיפור ביצועי אתר עבור מנועי החיפוש וגולשי האתר, וכדי לתקן שגיאות או טעויות סריקה (זחילה) או אינדוקס, אפשר ליצור איתי קשר בטלפון, בוואטסאפ או כאן, דרך האתר.
